Abstract
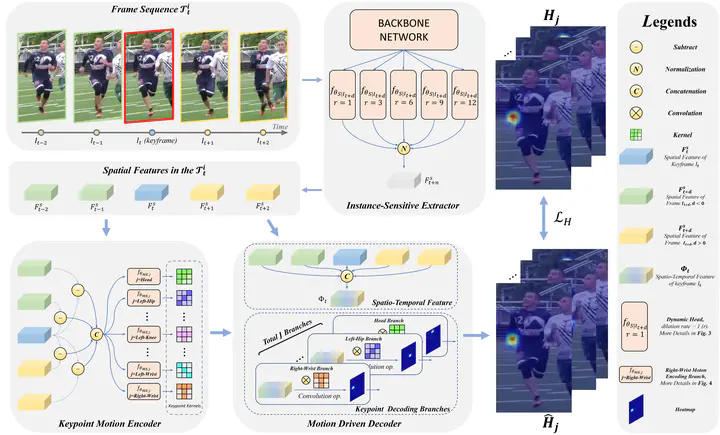
Estimating human poses from a video is at the foundation of many visual intelligent systems. Various convolutional neural networks have been proposed, achieving state‐of‐the‐art performance on different image datasets. However, most existing approaches are image based, which deliver unreliable estimations on videos since they fail to model temporal consistency across video frames. Recently, another line of work leverages temporal cues for multi‐frame person pose estimation, yet still in an instance‐unaware fashion, disregarding the specific traits of different instances (persons) or different joints. In this paper, we propose a novel approach to learn specific keypoint motion representations for each person, termed Personalized Motion‐Aware Network (PMAN). In the PMAN, we devise three components. (i) an Instance‐Sensitive Extractor that adaptively computes the spatial features according to human physical characteristics; (ii) a Keypoint Motion Encoder that separately generates convolution kernels with fine‐grained keypoint motion encoding; (iii) a Motion Driven Decoder that parses multi‐frame spatial features of the same person to provide precise human pose estimations. Extensive experiments on PoseTrack2017 and PoseTrack2018 datasets demonstrate that our approach greatly improves the performance of multi‐frame human pose estimation. It is worth mentioning that our approach surpasses the state‐of‐the‐art method by +1.7 mAP and achieves 82.9 mAP on PoseTrack2017 dataset.
Runyang Feng (封润洋)
PhD Student of Computer Science and Technology
Runyang Feng is currently a PhD student in School of Artificial Intelligence Jilin University. His research interests include Human Pose Estimation (2D), Video Understanding, Computer Vision, and Deep Learning.