Abstract
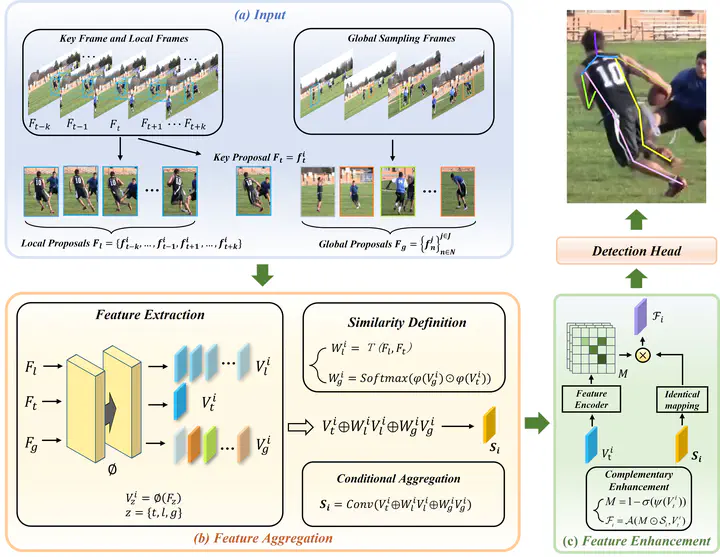
Multi-frame human pose estimation is at the core of many computer vision tasks. Although state-of-the-art approaches have demonstrated remarkable results for human pose estimation on static images, their performances inevitably come short when being applied to videos. A central issue lies in the visual degeneration of video frames induced by rapid motion and pose occlusion in dynamic environments. This problem, by nature, is insurmountable for a single frame. Therefore, incorporating complementary visual cues from other video frames becomes an intuitive paradigm. Current state-of-the-art methods usually leverage information from adjacent frames, which unfortunately place excessive focus on only the temporally nearby frames. In this paper, we argue that combining global semantically similar information and local temporal visual context will deliver more comprehensive and more robust representations for human pose estimation. Towards this end, we present an effective framework, namely global-local enhanced pose estimation (GLPose) network. Our framework consists of a feature processing module that conditionally incorporates global semantic information and local visual context to generate a robust human representation and a feature enhancement module that excavates complementary information from this aggregated representation to enhance keyframe features for precise estimation. We empirically find that the proposed GLpose outperforms existing methods by a large margin and achieves new state-of-the-art results on large benchmark datasets.
Runyang Feng (封润洋)
PhD Student of Computer Science and Technology
Runyang Feng is currently a PhD student in School of Artificial Intelligence Jilin University. His research interests include Human Pose Estimation (2D), Video Understanding, Computer Vision, and Deep Learning.